This article is the first one in a series titled Data structure zoo. Each article will give you a “working knowledge” of data structures that solve a particular problem. You won’t necessarily know how to implement each one, but you will have a good idea of the main characteristics of each solution and how to pick among them to solve your particular problem.
Today, I am writing about data structures to represent an ordered set. An ordered set is a common data structure that supports O(log N) lookups, insertions and removals. Ordered set is also sometimes used as an alternative to a hash map, for example in STL’s map.
Complexities of various operations on an ordered set are as follows:
- O(log N) insertion and removal.
- O(log N) check if contains a value.
- O(N) enumeration in sorted order.
- O(log N) to find the element in the set closest to some value.
- O(log N) to find k-th largest element in the set. This operation requires a simple augmentation of the the ordered set with partial counts.
- O(log N) to count the number of elements in the set whose values fall into a given range, in O(log N) time. Also requires a simple augmentation of the ordered set.
Now, let’s look at the different ways to implement an ordered set.
AVL Tree
In 1962, Russian mathematicians G.M. Adelson-Velsky and E.M. Landis presented a first solution to the ordered set problem, in a paper called “An algorithm for organization of information”. Given the ambitious title of the paper, it is clear that they knew that they were onto something big. The algorithm of Adelson-Velsky and Landis stores elements of the set in a binary search tree and ensures that the tree always remains perfectly balanced. The tree balances itself after each modification, hence it is an example of a self-balancing tree. Here is an example of an AVL tree:
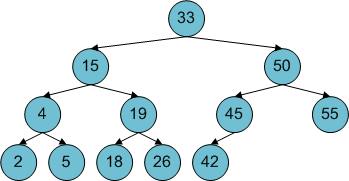
Notice that the tree is nicely organized so that the maximum number of steps to reach all nodes from the root is as small as possible. That is a very important property, which ensures that the complexity of basic operations such as lookups, insertions and removals is O(log N).
This idea is simple, but its implementation is not. The difficulty in the AVL tree design is inserting and removing nodes, while maintaining the balanced shape. You can read about the algorithm here. These are a few important things to know about how rebalancing works:
- Rebalancing the tree consists of O(log N) constant-time operations called rotations.
- Consequently, insertion or removal from the tree followed by rebalancing can be done in O(log N) time.
- Each rotation is a rearrangement of a small number of neighboring nodes in the tree.
Red-black Tree
Red-black tree is another popular algorithm for a self-balancing binary search tree, but one that makes slightly different trade-offs from the AVL tree. The main difference is that a red-black tree is not quite as neatly organized as an AVL tree. In an AVL tree, the longest path from a leaf to the root is at most one larger than the shortest path from a leaf to the root. In a red-black tree, the longest path to a leaf could be up to twice as long as the shortest path to a leaf.
So, you could say that a red-black is rebalanced more haphazardly. A lookup in a red-black tree may take longer, but on the plus side, the haphazard rebalancing is significantly cheaper. The tree tracks each node as either red or black. The color of the node is used in the complex rebalancing algorithm that I will not detail here, but that you can read all about here.
In practice, red-black trees tend to have slower lookups, but faster insertions and removals than AVL trees. Fast insertions and removals make red-black tree a popular data structure in system programming. For example, according to this article, the Linux kernel uses red-black trees to organize requests in various schedulers, the packet CD/DVD driver and the high-resolution timer, to track directory entries in an ext3 filesystem, and to lookup virtual memory areas, epoll file descriptors, cryptographic keys, and network packets. Also, red-black trees are used by the TreeSet in Java and map in STL.
Here is an example of a red-black tree. Notice that the tree has more levels than it absolutely would have to, but not by much (only by one level in this case):
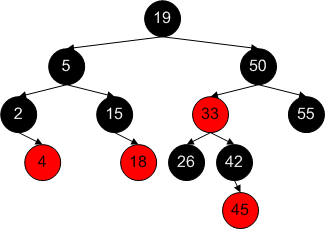
Treap
One interesting fact about self-balancing trees is that if you only insert random numbers, all of the tricky rebalancing is in fact unnecessarily. It can be mathematically proven that a sequence of random-number insertions is nearly guaranteed to fill the tree uniformly, so that it fairly nicely balanced. Self-balancing trees are only useful for special (but common) cases, such as when elements are inserted in an increasing or nearly-increasing order.
If we could ensure that elements are inserted in a random order, we would not need rebalancing. Of course, we cannot do that because in most scenarios we don’t have control over the order of insertions. But, we can still simulate a random insertion order, which is the main idea behind a treap.
Treap, just like an AVL tree or a red-black tree, is based on a binary search tree. As each value is inserted, treap assigns a priority to that value. Then, treap rearranges the tree as if values had been inserted in the priority order. So, values with low priorities will move closer to the root than values with higher priorities. In other words, a treap has a heap property with respect to priorities.
Treaps are significantly easier to implement than AVL or red-black trees, and have the same expected time complexity of operations. Theoretically, a treap could degenerate so that lookups become O(N) rather than O(log N), but the probability of that happening is extremely small.
Splay Tree
A splay tree is another self-balancing tree, but with an additional interesting property: the element that has been accessed most recently is at the root, and other recently accessed elements are also near the top. If we search for an element that we looked up recently, we will find it very quickly because it is near the top. This is a nice property because many real-world programs will access some values much more frequently than other values.
Unfortunately, there are two penalties that a splay tree pays for the nice cache-like behavior. The first penalty is that in the worst case, a lookup in a splay tree may take O(N) time, even though amortized over many operations, it is guaranteed to be O(log N) on average.
The second – even more serious – penalty is that lookups modify the tree as they perform rotations to move the recently accessed element to the root. The fact that a lookup performs O(log N) writes into the tree significantly adds to its cost on a modern hardware.
The FreeBSD operating system uses splay trees to organize memory pages in it its virtual memory manager. However, it seems that at least some contributors do not consider splay trees to be ideal for this purpose, and proposed a Google Summer of Code project to modify the virtual memory manager to use a different data structure.
Skip List
A skip list is a curiously different solution to the ordered set problem. A relatively new data structure, skip list was discovered in 1990 by professor of computer science at University of Maryland, William Pugh. Like a treap, skip list exploits randomness to implement an ordered set in a simple way. Skip list is essentially an ordered linked list… except that we add more links!
The problem with an ordered linked list is that to get into the middle of the list, we need to scan over half of the list, making the complexity of the lookup O(N). Skip list adds links that move more than one node forward, skipping over some nodes.
We use randomness to decide where to add links that skip over nodes. For a detailed description of how skip lists work and a C# implementation, see my earlier article on skip lists.
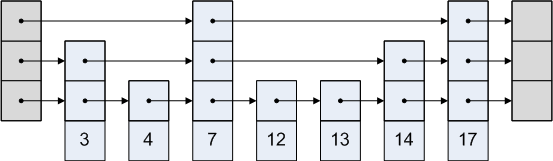
Pre-Balanced Tree
If you try to find information on pre-balanced trees, you will probably fail. That is because I don’t know what the real name of “pre-balanced trees” is, or even whether they have one.
It is simply a data structure that occurred to me while thinking about a problem in a programming contest. A pre-balanced tree is another possible solution to the ordered set problem. A pre-balanced tree has one huge advantage and one huge disadvantage over the other data structures mentioned in this article. The advantage is that it is brain-dead simple, even simpler than a treap or a skip list. The disadvantage is that we need to know the values that we will insert into the set ahead of time.
“Know the values that will be inserted in the future? This person is clearly crazy,” you are probably thinking. Well, I may be, but it still turns out that in many real-world problems, you actually know the values that will be inserted ahead of time. For example, a very common use case is to iterate over a sequence of elements, incrementally adding them into the set, and observing the state of the set in between the insertions.
In such cases, we can construct a fully balanced binary search tree that contains all values that will eventually be inserted. Initially, all values are “disabled”. Inserting a node enables it. To look up a value, find the node in the binary tree that contains the value. The set contains that value if such node is in the tree, and it is also enabled.
Here is an example of a pre-balanced tree, with nodes 18, 19 and 45 already inserted:
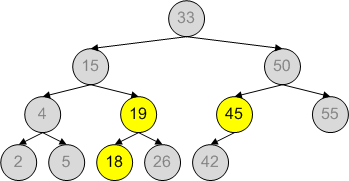

Tags: Algorithms

[…] Original post by Igor Ostrovsky […]
[…] Original post by Igor Ostrovsky […]
[…] Original post by Igor Ostrovsky […]
Nice overview. Looking forward to the rest of the series on data structures.
Thanks, just what I was looking for!
[…] public links >> blacktree Data structure ZOO: ordered set Saved by Spudgens on Sun 16-11-2008 David Banner: Stunt 101 Saved by eissimuf on Wed 05-11-2008 […]
[…] | 3 days ago Login and Register New Members First saved by Tanker940 | 7 days ago Data structure ZOO: ordered set First saved by sogrady | 14 days ago Advice on science fiction idea First saved by […]
[…] Data structure zoo: ordered set […]
Hi… Igor
I need to ask u a few tips as i am a novice programmer and require some guidance on starting up…. originally from an ECE background in UG level but now want to pick up a PG course in Comp Sc….
kindly mail me if you would be willing to guide me..
Thanks
Thanks, I hadn’t heard of Treaps before and they sound like a perfect candidate for my needs The name (combo between Tree and Heap) reminds me of Queaps (https://en.wikipedia.org/wiki/Queap), another ordered-set data struct you might want to add to this list.
The name (combo between Tree and Heap) reminds me of Queaps (https://en.wikipedia.org/wiki/Queap), another ordered-set data struct you might want to add to this list.