What is the time complexity of quicksort? The answer that first pops up in my head is O(N logN). That answer is only partly right: the worst case is in fact O(N2). However, since very few inputs take anywhere that long, a reasonable quicksort implementation will almost never encounter the quadratic case in real life.
I came across a very cool paper that describes how to easily defeat just about any quicksort implementation. The paper describes a simple comparer that decides ordering of elements lazily as the sort executes, and arranges the order so that the sort takes quadratic time. This works even if the quicksort is randomized! Furthermore, if the quicksort is deterministic (not randomized), this algorithm also reveals the input which reliably triggers quadratic behavior for this particular quicksort implementation.
The trick takes a dozen of code, works with nearly any quicksort routine, and only uses the quicksort via its interface! How cool is that? Here is a C# implementation of this idea:
class QuicksortKiller : IComparer<int> { Dictionary<int, int> keys = new Dictionary<int, int>(); int candidate = 0; public int Compare(int x, int y) { if (!keys.ContainsKey(x) && !keys.ContainsKey(y)) { if (x == candidate) keys[x] = keys.Count; else keys[y] = keys.Count; } if (!keys.ContainsKey(x)) { candidate = x; return 1; } if (!keys.ContainsKey(y)) { candidate = y; return -1; } return keys[x] - keys[y]; } }
This trick works well when applied to the .Net Array.Sort() method. The following chart displays the number of Compare() calls forced by QuicksortKiller when ran on an array of some size, as well as the number of Compare() calls that made by Array.Sort on a randomly-ordered sequence of the same length:
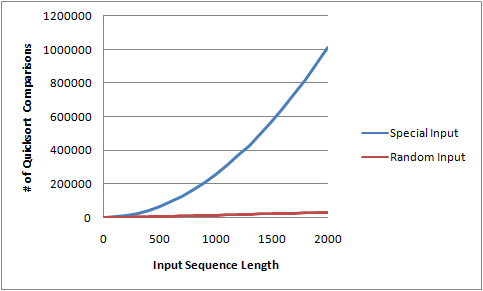
This chart clearly shows that the QuicksortKiller comparer triggers the quadratic behavior in Array.Sort.
How does it work?
QuicksortKiller’s trick is to ensure that the pivot will compare low against nearly all remaining elements. But, how can we detect which element is the pivot? We know quicksort will take the pivot and compare it against all other elements.
So, initially we consider all elements to be unsorted. The paper refers to them as "gas". When we compare two gas elements, we arbitrarily choose one of them, and freeze it to a value larger than any previously frozen values. We remember the other element as the pivot candidate. If the candidate is used in the next comparison with a gas element, we will make sure to freeze the pivot candidate, rather than the other element. That way, the pivot will be frozen within two comparisons against other elements.
Constructing a "Bad" Array
If the quicksort implementation is deterministic, and always takes the same steps on the same input, it is easy to generate an array that reliably triggers the quadratic behavior. The MakeBadArray method constructs an array that triggers the quadratic-time behavior of Array.Sort():
static int[] MakeBadArray(int length) { int[] arr = Enumerable.Range(0, length).ToArray(); Array.Sort(arr, new QuicksortKiller()); int[] ret = new int[length]; for (int i = 0; i < length; i++) { ret[arr[i]] = i; } return ret; }
How to defeat the Quicksort killer?
As the original paper explains, the adversary comparer works if the quicksort implementation checks an O(1) number of elements as pivot candidates. But, quicksort implementation that check more than O(1) elements are possible. For example, the quicksort might choose the median element as the pivot at each step, thus always geting a perfect split of the input sequence into two halves. Median can be found deterministically in O(N) running time, and so the total running time is always O(N logN). The median-based quicksort is rarely used in practice because it tends to have a larger constant than other quicksort implementations.
Another solution is to use a regular quicksort algorithm, and degrade to another sorting algorithm if quicksort is not working out. For example, if we reached a recursive depth of 10, and the size of our partition has not reduced by at least a half, we can just ditch quicksort and sort the partition using heapsort.

Tags: Algorithms

How to break quicksort…
You’ve been kicked (a good thing) – Trackback from DotNetKicks.com…
Ever heard of merge sort?
If you require GUARANTEED performance, i.e. that performance will not exceed an upper bound, heapsort is what you want.
Quicksort is great and all, but its inconsistency can be a killer where good performance is required, but bad performance is unacceptable.
And, on the upside, since heapsort requires no non-deterministic internal branching, in machine code compiled applications with a good optimising compiler you can be guaranteed that your pipelines stay saturated and that you get on average better performance than quicksort. The only real downside is that it has very bad cache locality.
The last few points aren’t really applicable to C#, but interesting to note, nonetheless.
Paco: of course I’ve heard of merge sort. Merge sort guarantees O(N log N) running time, but a typical implementation also requires O(N) additional memory. There are some implementations that do in-place merging and thus only require O(1) extra memory, while still guaranteeing O(N log N) running time. Unfortunately, the constant-memory implementations have a large constant, and also are rather complicated.
Merge sort guarantees O(N log N) running time, but a typical implementation also requires O(N) additional memory. There are some implementations that do in-place merging and thus only require O(1) extra memory, while still guaranteeing O(N log N) running time. Unfortunately, the constant-memory implementations have a large constant, and also are rather complicated.
Radix sort for the win!
Introsort?
http://www.en.wikipedia.org/wiki/Introsort
[…] Quicksort killer […]
[…] Quicksort killer [igoro.com] […]
[…] Quicksort killer […]
Pretty cool stuff!
The approach you suggested for defeating the adversary by finding median will end up using the same compare function and run in O(n^2) time instead of O(n) time, right?
If the quick sort uses the deterministic implementation, it is guaranteed to be O(N logN). For such algorithm, the adversary approach does not work.
Hi Igor,
Was that a response towards me?
I fail to understand your claim of using a linear time median-finding algorithm to defeat the adversary. Could you please help me understand? Do you have this algorithm in mind for that approach?
http://en.wikipedia.org/wiki/S....._algorithm
Hi Anil,
Yes, my response was meant for you. And yes, I was referring to the linear selection algorithm that you linked to.
A typical quicksort implementation will pick the pivot in some “naive” way: pick the first element, or the middle element, or a pseudo-random element, etc. Such quicksort will get beaten by the adversary comparer.
However, you can actually pick the perfect pivot by computing the median of the array. Finding this pivot takes O(N) time. Using median find to select the pivot, the total running time of the quicksort is O(N logN) in the worst case – there are O(log N) recursion levels, and each level takes O(N) time.
I hope that is clear. By the way, the Wikipedia article you linked to also mentions the possibility of quicksort with worst case O(N log N): see the Important Notes section.
You might wonder why the median-based quick sort defeats the adversary. The reason is that the deterministic quicksort looks at O(N) elements before picking the pivot. And that is enough to guarantee that a good pivot will be chosen, even if the comparer acts as an adversary.
Igor, I sincerely appreciate your awesome explanation.
I got this point when I read your article for the first time though. I understand the role of finding median in this scenario.
My only concern is that even finding median relies on the same ‘Compare’ function (the adversarial Compare) since the order between these elements is defined only by that function and uses the same partitioning technique as quicksort.
Now, don’t you think the median finding algo will also get screwed up badly and take O(N^2) instead of O(N)?
Once it takes O(N^2), quicksort will also takes O(N^2 log N).
Some quicksorts use median-of-3 algo. But, that will not serve the purpose here. Am I missing something here? Thanks again. If I am being a pain, please ignore this comment
Hi Anil,
A typical median algorithm takes O(N) in the average case. But, as you say, the median algorithm will take O(N^2) for some bad cases.
However, there is a variant of the median algorithm that takes O(N) in the worst case. That’s the algorithm on the Wikipedia page that you linked to.
That algorithm has no “bad case” for the adversary to exploit.
Igor
Got you. Sorry for the confusion.
can you please give me an example of any industrial field,educational field or any field which uses quick sort’s algorithm to get some output.
Others have mentioned Heap Sort and Radix Sort as alternatives to Quick Sort. The ultimate in the Heap-Radix direction is the Distributive Partition Sort
( note: the article’s initial split on the median is not essential. It comes from the originator’s implementation; and reduces the likelihood of in trouble with non-uniform data. The original did not recur all the way to step 1, but only to a simplified step 2 on each bucket with more than one items. )
Basically a Bucket Sort where the number of buckets is equal to the number of elements to be sorted. The Bucket Selector function chooses the bucket based on the Key, Minimum, Maximum and number of elements.
Expected case: O(N); Worst case as defined: O(N * log N); Worst case with lazy code: O(N ^ 2)
As with Quick Sort, the lazy comparer/selector is the one prone to the worst case.
e.g., if the selector only looks at the first byte that is different across all keys, then it is easy to build a killer data set. Such a lazy selector would be O(N ^ 2), separating out one record per pass.
You could think of it as a Radix Sort where the largest possible key is a single digit in the chosen Radix.
Sadly, it generally requires high constants, so you really need a large data set to make it worth the trouble.
rakesh: Quick sort is one of the popular sorting algorithms, soit is used all over the place. For example, whenever you sort files in a file manager (e.g., Windows Explorer) by date, the file manager could reasonably be using quick sort.
Jesse: Distributive partitioning sort seems like an interesting algorithm – I wasn’t aware of it. When splitting on median, it seems that the algorithm is O(N logN) in the worst case. Without that splitting, a killer set would be pretty easy to build, especially if the keys are floating point numbers.
E.g.: (1e100, 1e98, 1e96 … 1) would take O(N^2). On the other hand, this form of a ‘killer set’ cannot be generalized very far, since doubles only go up to 1e300 or so.
may i know how to get time complexity for a particular example using quick sort?for example we have to sort this these elements like 60,59,70,13,5,80,12,if we sort it using quick sort hw to find time complexity plz reply plzzz
M. Douglas McIlroy: A Killer Adversary for Quicksort. Softw., Pract. Exper. 29(4): 341-344 (1999)
Well, if you had access to comparer, you can just add Thread.Sleep with a quadratically increasing parameter so not much point for going to all this trouble for “defeating” quickshort. It would have been interesting however if you can measure response times of sample inputs and create a bad array for deterministic quicksort.